https://www.developing.dev/p/openai-codex-tech-lead-on-how-his - Hero Quest
Friday, March 13, 2026
Thursday, March 12, 2026
Wednesday, March 11, 2026
What did Paul Erdos quip about aliens and R(6,6)
The statement “AlphaEvolve has helped establish new lower bounds for five classical Ramsey numbers” is significant because it represents progress in one of the hardest areas of combinatorics and theoretical mathematics. To understand why it matters, we need to unpack a few pieces.
1. What Ramsey numbers are
Ramsey numbers come from Ramsey Theory, which studies when order must appear inside randomness.
A Ramsey number (R(m,n)) asks:
What is the smallest number of people needed at a party so that either at least (m) people all know each other or at least (n) people are all strangers?
Example:
Ramsey number R(3,3) = 6
Meaning:
In any group of 6 people, there must be either:
3 mutual friends, or
3 mutual strangers.
For larger numbers (like (R(5,5)), (R(6,6))), the values become extremely hard to determine.
2. Why Ramsey numbers are notoriously difficult
Most Ramsey numbers are unknown.
For example:
Ramsey number R(5,5) is only known to be between 43 and 48.
For larger ones, the uncertainty ranges can be hundreds or thousands wide.
Mathematicians usually try to prove:
Lower bound: the number is at least some value
Upper bound: the number is at most some value
Closing the gap between these bounds is a major research challenge.
3. What a “new lower bound” means
If researchers show a larger lower bound, it means they discovered a specific structure that avoids the forced pattern longer than previously known.
Example idea (simplified):
Previously:
Largest known graph avoiding the pattern: N = 42
New result:
Someone constructs one with N = 44
Now we know:
[
R(m,n) > 44
]
That’s a new lower bound.
Even improving by 1 can be a major breakthrough.
4. What AlphaEvolve did
AlphaEvolve is an AI system developed by Google DeepMind that searches for mathematical structures.
Instead of proving theorems directly, it:
Generates candidate graphs
Tests whether they avoid certain forbidden patterns
Evolves better structures using search and optimization
Using this process, it discovered larger graphs without certain cliques or independent sets, improving known bounds.
So when you read:
“AlphaEvolve established new lower bounds for five classical Ramsey numbers”
it means:
The AI found better constructions than humans previously knew.
Those constructions push the known limits of these Ramsey numbers.
5. Why this is a big deal
There are several reasons mathematicians care:
1. These problems can remain unsolved for decades
Some Ramsey bounds haven't improved in 20–30 years.
2. The search space is astronomically large
For graphs with 40–50 vertices there are more possibilities than atoms in the universe.
AI can explore this space far more aggressively than humans.
3. It shows AI can assist pure mathematics
Similar to:
AlphaGo (games)
AlphaFold (biology)
AlphaEvolve suggests AI may become a tool for discovering new mathematical objects.
✅ In simple terms:
The significance is that an AI system discovered better examples of large pattern-avoiding graphs, which pushed forward the known limits of several Ramsey numbers—something mathematicians had struggled to improve for years.
If you're interested, I can also explain how the AI actually searches the graph space (it’s a fascinating mix of evolutionary algorithms + combinatorics + SAT solving).
How AI like AlphaEvolve searches for Ramsey constructions
How AI like AlphaEvolve searches for Ramsey constructions
Think of the problem as searching for a special graph with (N) vertices where:
there is no clique of size (m) (no group where everyone connects to everyone)
there is no independent set of size (n) (no group where nobody connects)
A graph like that proves:
[
R(m,n) > N
]
because you’ve shown the forbidden pattern does not yet appear at size (N).
The search challenge
The number of possible graphs on (N) vertices is:
[
2^{\binom{N}{2}}
]
For (N=40):
[
2^{780} \approx 10^{234}
]
That’s far beyond brute-force enumeration.
The strategy used by systems like AlphaEvolve
AI systems combine three main ideas.
1. Evolutionary search
Candidate graphs are treated like organisms.
Steps:
Generate random graphs
Score them (how close they are to violating the rule)
Mutate edges
Keep better ones
Repeat millions of times
This is similar to Evolutionary Algorithm.
2. Clever scoring functions
A graph is not just valid or invalid. It gets a score like:
number of forbidden cliques
number of forbidden independent sets
how close it is to violating constraints
The AI gradually reduces these violations.
3. Structure discovery
Some systems learn patterns humans use, such as:
symmetric graphs
circulant graphs
block constructions
These reduce the search space drastically.
The result: AI finds very large graphs that avoid patterns, pushing the lower bound higher.
Has Ramsey theory mattered in real life?
Here’s the surprising part:
Ramsey theory rarely solves practical problems directly.
Instead, it tells us something deeper:
Certain patterns are mathematically unavoidable.
This has influenced several real-world fields.
1. Communication networks and internet routing
Ramsey-type ideas appear in network reliability.
Large networks inevitably contain:
clusters of tightly connected nodes
clusters of mutually disconnected nodes
This affects:
distributed systems
routing resilience
network partition detection
These ideas are studied in Graph Theory.
Example:
In massive peer-to-peer networks, designers know certain substructures will appear regardless of randomization.
Ramsey theory gives theoretical limits on how long disorder can persist.
2. Error-correcting codes and data storage
The philosophy behind Ramsey theory influenced work in:
Coding Theory
In storage systems:
avoiding specific patterns of interference
guaranteeing certain patterns appear
These combinatorial bounds guide how large codes can be.
3. Circuit design and hardware testing
In very large circuits, engineers study unavoidable patterns of signal paths.
Combinatorial bounds (related to Ramsey ideas) help analyze:
worst-case interference
cross-talk patterns
This appears in theoretical work related to Extremal Combinatorics.
4. Social networks (friend/enemy paradox)
The classic interpretation:
In large groups, cliques or anti-cliques inevitably form.
This idea has been used in modeling:
online communities
polarization
coalition formation
It’s conceptually related to work in Network Science.
Cultural and philosophical influence
Ramsey theory has had huge philosophical impact, even if practical applications are rare.
It suggests something profound:
Complete randomness cannot persist in large systems.
Order inevitably emerges.
This idea fascinated many thinkers.
Example in popular science
The idea appears in the famous book:
The Improbability Principle
It discusses why surprising patterns appear inevitably in large datasets.
Literary echo
The concept that order inevitably emerges from chaos appears in fiction exploring mathematics and patterns.
For example:
Gödel, Escher, Bach discusses deep mathematical structures that appear inevitably in complex systems.
Why mathematicians care so much
Ramsey numbers are famous because they represent the edge of human mathematical ability.
Even small cases are brutally difficult:
Ramsey number R(4,5)
Ramsey number R(5,5)
Determining exact values requires:
deep combinatorics
massive computation
clever constructions
When an AI system improves even one bound, mathematicians pay attention.
The deeper future significance
The real importance of systems like AlphaEvolve may be how mathematics is done.
Historically:
humans proved theorems
computers checked cases
Now AI may discover mathematical objects humans would never think of.
Similar shifts already happened with:
AlphaFold in biology
AlphaGo in games
Ramsey problems might become one of the first areas where AI meaningfully expands human mathematical discovery.
✅ In short
Ramsey theory rarely fixes a direct real-world problem.
Its importance is deeper:
it reveals limits of randomness
it shapes combinatorics and network theory
and now it may become a playground for AI-driven mathematical discovery.
If you're curious, I can also show you something fascinating:
Why mathematicians suspect (R(6,6)) might be between ~102 and ~165 — and why computing it could require centuries of CPU time.
Why the Ramsey number (R(6,6)) is so hard to compute
Why the Ramsey number (R(6,6)) is so hard to compute
The problem
The number Ramsey number R(6,6) asks:
What is the smallest number (N) such that every graph with (N) vertices contains either:
a clique of size 6, or
an independent set of size 6?
We know today that:
[
102 \le R(6,6) \le 165
]
But the exact value is unknown.
Even after decades of work in Combinatorics, nobody has determined it.
Why this problem explodes in difficulty
Number of possible graphs
A graph with (N) vertices has
[
\binom{N}{2}
]
possible edges.
Each edge can be present or absent, so the total number of graphs is:
[
2^{\binom{N}{2}}
]
For (N = 102):
edges = 5151
graphs =
[
2^{5151}
]
That is roughly:
[
10^{1550}
]
For comparison:
atoms in the observable universe ≈ (10^{80})
So brute force is impossible.
Even checking ONE graph is expensive
To verify a candidate graph avoids the forbidden patterns, you must check:
all possible 6-vertex subsets
The number of subsets is:
[
\binom{102}{6} = 1.19 \text{ billion}
]
Each must be tested to see if it forms:
a clique
an independent set
So checking one graph already requires billions of checks.
Why computers still help
Instead of brute force, researchers use clever techniques from Graph Theory.
These include:
1. Symmetry reduction
Many graphs are identical under vertex relabeling.
Algorithms only explore unique structures, eliminating duplicates.
2. SAT solvers
Researchers convert the problem into a giant logical formula and solve it with tools from Boolean Satisfiability.
This method helped compute:
Ramsey number R(5,5) bounds
Ramsey number R(4,5) exactly
3. Clever constructions
Instead of searching randomly, mathematicians design structured graphs such as:
circulant graphs
Paley graphs
algebraic constructions
These often produce the best lower bounds.
Why AI changes the game
Systems like AlphaEvolve can:
explore billions of candidate structures
mutate graphs intelligently
discover constructions humans might never try
Instead of proving the exact number, AI pushes the lower bound upward.
Each improvement means:
“We found an even larger graph with no forbidden structure.”
Why R(6,6) might take centuries without breakthroughs
To prove the exact value, mathematicians must show:
A graph exists with (N-1) vertices avoiding the pattern
Every graph with (N) vertices contains it
The second step is extremely difficult.
It may require checking astronomically many possibilities, even with pruning.
The famous quote about Ramsey numbers
The legendary mathematician Paul Erdős once joked:
If aliens demanded the value of (R(5,5)), we should mobilize all computers.
If they demanded (R(6,6)), we should try to destroy the aliens.
This captures how explosively hard these problems become.
Why mathematicians still chase them
Ramsey numbers are like the Mount Everest of combinatorics.
They represent the frontier of Ramsey Theory:
very simple to state
brutally hard to solve
deeply connected to randomness and structure
✅ The big takeaway
The mystery of (R(6,6)) isn’t just about one number.
It represents a deeper truth:
Even extremely simple mathematical rules can produce complexity beyond brute-force computation.
That’s exactly why tools like AI search systems are becoming so exciting.
If you want, I can also show you something fascinating:
Why mathematicians believe most Ramsey numbers grow roughly like (4^{n/2}) — and why proving that is still unsolved. It’s one of the strangest patterns in combinatorics.
Ramsey not modular
Great intuition — many people (including mathematicians) have asked something very similar. Unfortunately, Ramsey numbers don’t decompose nicely into smaller ones like (R(3,3)). But the reason why is actually very illuminating.
First: what (R(3,3)) tells us
The classical result
Ramsey number R(3,3) = 6
means:
Any graph with 6 vertices must contain either
• a triangle (3-clique)
• or a 3-vertex independent set.
Graphically, it means small groups force triangles.



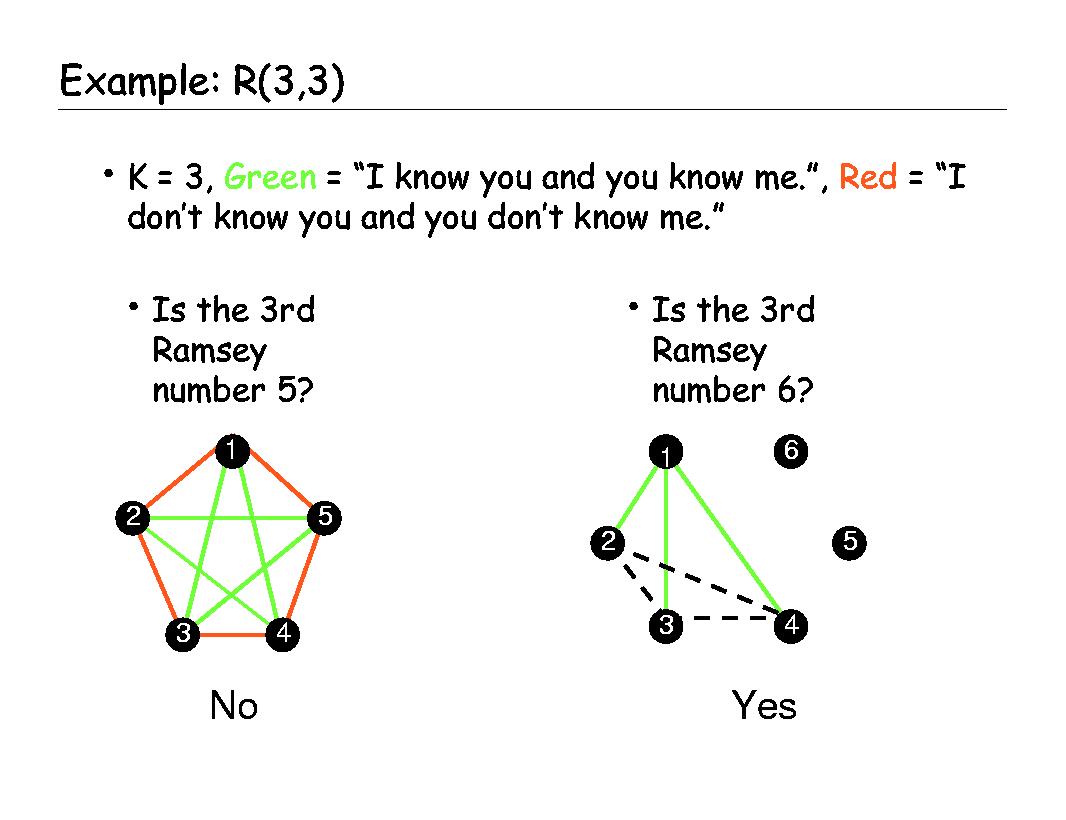
This is manageable because the graph size is tiny.
Why we can't build (R(6,6)) from (R(3,3))
Your idea would look like:
Build clusters of size 6 (because (R(3,3)=6))
Connect those clusters carefully
Avoid forming a 6-clique or 6-independent set globally
But the problem is interactions between clusters create new structures.
Example intuition
Suppose you build groups:
Group A
Group B
Group C
Group D
Even if each group avoids large cliques internally, edges between groups combine to create larger cliques.
For instance:
A: 2 vertices
B: 2 vertices
C: 2 vertices
If edges connect across groups in the right pattern, you suddenly get a 6-clique even though no group had one.
So local guarantees don’t compose cleanly.
Ramsey theory is fundamentally global
Ramsey problems behave differently from many mathematical objects.
They are not modular.
In fields like:
Number Theory
Group Theory
you often break problems into smaller pieces.
But in Ramsey Theory, the entire graph interacts in complicated ways.
A small pattern anywhere can combine with others to create the forbidden structure.
What mathematicians actually do instead
Rather than decomposing, they use structured constructions.
Example approaches:
1. Circulant graphs
Vertices are arranged in a circle and edges follow modular arithmetic rules.
Example:
connect i to j if (j-i mod n) ∈ S
This creates symmetry that helps avoid patterns.
2. Algebraic graphs
Using finite fields or quadratic residues (Paley graphs).
These come from deep algebra in Finite Field Theory.
3. Computer-guided search
Systems like
AlphaEvolve
try millions of mutations on candidate graphs.
They evolve structures that avoid forbidden patterns.
The closest thing to your idea
There is a recursive inequality discovered by
Frank P. Ramsey
[
R(s,t) \le R(s-1,t) + R(s,t-1)
]
For example:
[
R(6,6) \le R(5,6) + R(6,5)
]
This helps compute upper bounds.
But it still doesn't let us reduce everything to (R(3,3)).
Why your instinct is still valuable
Your idea is actually related to a major concept in combinatorics:
hierarchical structure building
Many breakthroughs happen when mathematicians find clever ways to assemble small structures into large ones without triggering forbidden patterns.
That’s exactly what:
extremal graph theory
probabilistic combinatorics
AI search systems
are trying to do.
A surprising fact about Ramsey numbers
The true values grow extremely fast.
Research suggests roughly:
[
R(n,n) \approx 4^{n/2}
]
This result comes from work by
Paul Erdős
using the probabilistic method.
Meaning:
Even if we can't construct the graphs explicitly, random graphs prove they exist.
✅ Key insight
Your idea would work if Ramsey structures were local.
But they’re global emergent patterns — the whole graph must be considered at once.
That’s exactly why even a problem as simple as (R(6,6)) has resisted solution for decades.
If you'd like, I can also show you something mind-blowing:
There are Ramsey numbers that are literally impossible to compute even with all computers in the universe.
It comes from a connection to logic and the limits of provability.
How many hard problems are really waiting for better search, not just bigger models?
How many hard problems are really waiting for better search, not just bigger models?
The question has become a serious discussion in AI research recently. The AlphaEvolve Ramsey result is a good example of the “better search” paradigm, which is quite different from scaling neural networks.
Let’s unpack it.
1. Bigger models vs better search
In modern AI there are two broad strategies:
Bigger models
Train massive neural networks with more data and compute.
Examples:
GPT‑4
Gemini
These work well for:
language
perception
coding
reasoning approximations
But they don’t directly explore large discrete spaces.
Better search
Instead of predicting answers, the system explores possibilities and verifies them.
Famous examples:
AlphaGo used Monte Carlo tree search
AlphaFold searched structure space
AlphaEvolve searches mathematical constructions
Here the AI:
Generates candidate solutions
Evaluates them with strict rules
Iteratively improves them
This is closer to scientific discovery than prediction.
2. Yes — the Ramsey improvement was a search breakthrough
The improvement to Ramsey bounds was not because of a larger neural network.
It happened because the system could:
explore enormous graph spaces
mutate structures intelligently
keep partial improvements
This falls into Combinatorics, where many problems are essentially search over huge spaces.
So the quote you saw is quite accurate.
Many hard problems are like:
“The solution exists somewhere in a gigantic space of possibilities.”
3. Fields where better search may unlock breakthroughs
These areas are widely believed to be ripe for AI-guided search.
Extremal combinatorics
Area of:
Extremal Combinatorics
Problems often ask:
What is the largest structure avoiding some pattern?
Examples likely to improve:
Ramsey numbers
Turán-type graph problems
hypergraph constructions
These are perfect for evolutionary search.
Coding theory
Field:
Coding Theory
Goal: find codes with best error-correcting properties.
Historically many codes were discovered by clever search.
AI could find:
new record-breaking codes
improved storage systems
better satellite communication schemes
Materials science
Huge design space for molecules and crystals.
AlphaFold already showed the power of AI in biology.
Next targets include:
superconductors
catalysts
battery materials
These are essentially search in chemical configuration space.
Algorithms
AI could discover new algorithms.
Some early examples already happened with:
AlphaTensor
AlphaTensor discovered faster matrix multiplication algorithms for certain sizes.
That shocked many mathematicians.
4. Why search is suddenly becoming powerful
Three changes happened recently:
Massive compute
We can evaluate billions of candidates.
Hybrid AI systems
Neural networks guide the search.
Fast verification
Computers can instantly check if a candidate is valid.
That combination is extremely powerful.
5. Problems people think AI search may solve next
Researchers often mention:
Small Ramsey numbers
Especially:
Ramsey number R(6,6) bounds
hypergraph Ramsey numbers
Sphere packing variations
Related to:
Sphere Packing Problem
New constructions might appear.
New error-correcting codes
Important for:
deep space communication
storage systems
quantum computing
Circuit optimization
Finding minimal circuits for cryptographic operations.
Huge search space.
6. About SolveAll.org
Yes — SolveAll has been discussed in the AI research community.
The idea behind it is roughly:
Build AI systems specifically designed to attack unsolved scientific and mathematical problems.
Their philosophy aligns with the search paradigm:
structured problem databases
automated conjecture generation
algorithmic exploration
verification loops
It’s similar in spirit to projects like:
Lean
Coq
but aimed at problem-solving pipelines rather than proof verification.
The general concept is gaining traction because of results like:
AlphaFold (biology)
AlphaTensor (algorithms)
AlphaEvolve (combinatorics)
7. The deeper idea: “scientific search engines”
Some researchers think future AI systems will look like:
generate hypothesis
→ test
→ refine
→ repeat
This mirrors the scientific method.
Instead of asking AI for answers, we ask it to explore possibility space.
8. A provocative prediction
Many scientists now think the first major math breakthrough by AI will not be a proof like the:
Riemann Hypothesis
Instead it will likely be something like:
discovering a new combinatorial construction
finding new algorithms
optimizing structures humans overlooked
Exactly the type of problem that better search excels at.
✅ The key insight from that quote
Some problems are hard because:
we don’t understand them
But many are hard simply because:
The search space is enormous and humans can only explore tiny parts of it.
AI is beginning to change that.
If you're interested, I can also show you 5 famous open problems that are almost purely search problems (and therefore extremely likely to fall to AI in the next 10–20 years). They’re fascinating because they look deceptively simple.
“search-dominated” problems
Here are 5 famous open problems that are widely believed to be “search-dominated” problems—meaning the main barrier is exploring enormous spaces of possibilities rather than inventing completely new mathematics. These are exactly the types of problems where AI-guided search systems (like AlphaEvolve-style systems) could realistically make breakthroughs.
1. Determining the exact value of (R(6,6))
Ramsey number R(6,6)
Field: Ramsey Theory
We currently know:
[
102 \le R(6,6) \le 165
]
Meaning:
A graph with 101 vertices exists with no 6-clique or 6-independent set.
But by 165 vertices, such a structure must exist.
The challenge:
The number of graphs on ~100 vertices is astronomically large.
But many are structurally similar.
AI systems could:
search for larger constructions (raise lower bounds)
help prove absence structures with SAT solvers
guide symmetry discovery
Many combinatorialists think this is a prime candidate for AI progress.
2. Better sphere packing constructions in high dimensions
Sphere Packing Problem
The problem asks:
What is the densest way to pack spheres in (n) dimensions?
Visual intuition in 3D:



Known spectacular result:
E8 lattice
But for many dimensions (9–30 especially):
best packings are unknown
improvements usually come from clever constructions
AI could search:
lattice structures
algebraic symmetries
packing configurations
This is extremely similar to Ramsey searches.
3. Better error-correcting codes
Coding Theory
Goal:
Maximize how many errors a code can detect or correct.
These are used in:
deep space communication
SSD storage
satellite transmission
QR codes
Visual idea:



Most record-holding codes historically came from:
clever search
algebraic construction
AI could discover:
new record codes
shorter codes with same error tolerance
Even small improvements have massive engineering impact.
4. Faster matrix multiplication algorithms
Matrix multiplication speed is determined by an exponent ( \omega ).
Current best:
[
\omega < 2.372
]
This matters everywhere:
graphics
machine learning
simulations
cryptography
An AI already surprised mathematicians here:
AlphaTensor
AlphaTensor discovered new multiplication algorithms for specific matrix sizes.
These were not known before.
Researchers suspect AI could:
find better algorithms
push the theoretical exponent lower
Because the problem is fundamentally search over algebraic decompositions.
5. Minimal circuits for cryptography
Cryptographic primitives often depend on:
Boolean circuits
logic gate networks
Example fields:
Cryptography
Circuit Complexity
Goal:
Implement operations with the fewest gates possible.
Why it matters:
faster encryption
lower power hardware
smaller chips
But the design space is enormous.
AI-guided search could explore:
millions of circuit configurations
optimized gate layouts
Why these problems are ideal for AI
They share 4 properties:
Huge search spaces
Clear objective functions
Fast verification
Structured symmetries
This is exactly the environment where systems like:
AlphaGo
AlphaFold
AlphaEvolve
perform extremely well.
The bigger shift happening in science
Historically:
human intuition → theorem
Now we increasingly see:
AI search → candidate structure
human → explanation/proof
AI becomes a discovery engine, not just a reasoning tool.
Some researchers call this the rise of computational discovery.
✅ My personal prediction
In the next 10–20 years, AI search systems will likely:
improve several Ramsey bounds
discover new codes
find better matrix multiplication algorithms
design novel materials
But the biggest impact may be discovering mathematical objects humans didn’t know to look for.
If you want, there’s an even deeper idea behind this trend:
Some mathematicians think many unsolved problems are really “compression problems” rather than reasoning problems.
That idea connects Ramsey theory, AI search, and even physics—and it’s pretty mind-bending.
Tuesday, March 10, 2026
Saturday, March 07, 2026
MX and vector world
VMXDOTP: A RISC-V Vector ISA Extension for Efficient Microscaling (MX) Format Acceleration
Takeaways:
1. Microscaling (MX) data formats, based on block floating-point (BFP) representations, have emerged as a promising solution to reduce data volumes while preserving accuracy. However, MX semantics are poorly aligned with vector execution: block scaling and multi-step mixed-precision operations break the regularity of vector pipelines, leading to underutilized compute resources and performance degradation.
2. As bitwidths decrease, preserving model accuracy becomes increasingly challenging due to the reduced dynamic range and precision [1]. To alleviate this trade-off, block-scaled data formats have emerged as a compelling solution. By associating a shared scale factor with a block of low-bitwidth elements, these formats preserve high dynamic range while retaining the benefits of a compact representation
3. While the memory savings of MX formats are a direct consequence of their compact design, their computational benefits are often overlooked. MX quantization is frequently treated as a storage-only compression approach to alleviate memory bottlenecks, requiring decompression to wider formats before computation [4], [5]
Math
Mathematics for computer science from MIT course
the-deep-link-equating-math-proofs-and-computer-programs - "Curry-Howard correspondence posits that two concepts from computer science (types and programs) are equivalent, respectively, to propositions and proofs — concepts from logic."
Towards a Lean proof of Fermat’s Last Theorem
https://x.com/zk_monk/status/2030305129493049748 - Everything you wanted to know about Maths
Friday, March 06, 2026
Books on Algorithms
Connecting to Books on Algorithms
If you want a book that collects these algorithms and explains their reasoning, here are the most relevant:
🔹 The Algorithm Design Manual — Steven Skiena slides Introduction to Algorithm Design
-
Organizes algorithms by problem type
-
Emphasizes design patterns (very close to modes of thinking)
-
Includes stories behind each major algorithm
🔹 Introduction to Algorithms — Cormen, Leiserson, Rivest, Stein (CLRS) Introduction to Algorithms
-
Covers most of the “10 foundational algorithms”
-
Each algorithm is presented with:
-
Description
-
Correctness proof (invariants)
-
Complexity analysis (optimization)
-
🔹 Concrete Mathematics — Graham, Knuth, Patashnik Concrete Mathematics
-
Focuses on mathematical foundations underlying algorithms
-
Shows how proofs and thinking modes map to efficient computation
five core modes of mathematical thinking
most discoveries come from a small number of thinking patterns. These patterns generate both algorithms and theorems.
Below are five core modes of mathematical thinking that produce a huge fraction of results in mathematics and computer science.
1. Decomposition (Break the Problem Apart)
Idea: break a difficult problem into smaller simpler pieces.
This is one of the most powerful reasoning tools.
Example algorithm:
-
Merge sort
How it works:
big problem
↓
split into smaller problems
↓
solve each
↓
combine answers
This idea appears everywhere:
-
divide-and-conquer algorithms
-
mathematical induction proofs
-
dynamic programming
Many complex algorithms are just repeated decomposition.
2. Invariants (What Never Changes)
An invariant is something that stays constant during a process.
Example:
Euclidean algorithm
Key invariant:
Even though the numbers change, the gcd remains the same.
Invariant thinking appears in:
-
loop correctness proofs
-
puzzle solving
-
game theory
-
algorithm design
Many elegant proofs rely on discovering one hidden invariant.
3. Symmetry
Symmetry reduces complexity because identical situations behave the same.
Example theorem:
Pythagorean theorem
Many proofs exploit symmetry of shapes.
Symmetry also appears in:
-
physics laws
-
group theory
-
graph algorithms
Recognizing symmetry often collapses huge problems into small ones.
4. Recursion / Self-Reference
A structure defined in terms of itself.
Example algorithm:
-
Quicksort
Example recursive idea:
solve(n):
solve(n-1)
Examples in mathematics:
-
factorial definition
-
Fibonacci sequence
-
fractals
-
recursive data structures
Recursion allows infinite structures to be described with finite rules.
5. Optimization (Best Possible Solution)
Many problems ask:
What is the best possible outcome?
Examples:
-
shortest path
-
minimum cost
-
maximum profit
Example algorithm:
-
Dijkstra's algorithm
Optimization thinking appears in:
-
operations research
-
machine learning
-
economics
-
logistics
It often leads to greedy algorithms or dynamic programming.
The Deep Pattern
Most algorithms and theorems combine these ideas.
Example:
Shortest path algorithms use:
-
decomposition
-
invariants
-
optimization
Sorting algorithms use:
-
recursion
-
decomposition
Proofs often combine:
-
invariants
-
symmetry
A Mental Toolkit
You can think of mathematical creativity like this:
Decompose the problem
Look for invariants
Use symmetry
Apply recursion
Optimize the result
These five tools generate huge portions of mathematics and algorithms.
✅ Interesting observation
Many of the deepest open problems — like
P versus NP problem — revolve around understanding how these patterns interact in computation.
Proof, Theorem and ALgorithm
Here’s a roadmap of books and university‑level courses that are great for starting and deepening your journey into proof thinking, theorems, and algorithmic thinking — from beginner to advanced.
📘 Introductory Books (Building Proof & Logic Skills)
🔹 How to Think Like a Mathematician — Kevin Houston
A gentle guide to learning mathematical language and basic proof strategies. Great for beginners transitioning to formal math.
🔹 Book of Proof — Richard Hammack
Designed specifically to teach how to read and write proofs, with lots of examples and exercises.
🔹 How to Prove It — Daniel J. Velleman
Structured proof techniques — induction, contradiction, cases — ideal for writing your own proofs.
🔹 The Art of Problem Solving / Problem-Solving Strategies — Paul Zeitz / Arthur Engel
Not just proof methods but thinking like a mathematician and tackling rich problems. (Commonly recommended on math forums listing proof books.)
📚 Other accessible choices
-
Mathematical Thinking: Problem‑Solving and Proofs — D’Angelo & West
-
How to Read and Do Proofs — Daniel Solow
These all help you learn to think like a mathematician and understand why proofs matter.
📗 Discrete Mathematics & Algorithm Foundations
These texts are standard in CS programs because they mix proofs, logic, and algorithm thinking:
🔹 Discrete Mathematics and Its Applications — Kenneth Rosen
Covers logic, proof techniques, sets, combinatorics, graph theory and more — excellent for algorithmic thinking.
🔹 Concrete Mathematics — Graham, Knuth & Patashnik
A classic blend of continuous and discrete math used in analysis of algorithms.
🔹 Courses covering discrete math & proofs
-
Introduction to Discrete Mathematics for Computer Science (Coursera) — includes logic, induction, recursion, invariants, and proofs connected with algorithms.
-
Mathematical Thinking in Computer Science (Coursera) — part of the discrete specialization; focuses on proof, logic, algorithm design, and reasoning.
📙 Algorithm & Theory Classics
Once you’re comfortable with proofs and discrete math, these books take you deeper into algorithm design and correctness:
📌 Introduction to Algorithms — Cormen, Leiserson, Rivest & Stein (a.k.a. CLRS)
The standard algorithms text; formal and proof‑oriented, with many correctness proofs.
📌 The Algorithm Design Manual — Steven Skiena
More intuitive, with lots of design patterns and problem‑solving emphasis (less formal, but great practice).
📌 Algorithms — Robert Sedgewick & Kevin Wayne
Accessible and thorough, with implementations and analysis.
📘 Advanced Theoretical Paths
If you love proofs and want to go beyond basics:
🔹 Combinatorics: The Rota Way – (Advanced text, more abstract)
A graduate level combinatorics book packed with deep theorems and proof techniques.
🔹 Formal logic & proof theory texts
Topics like sequent calculus and formal proof systems sit between math and CS and help develop deep rigor.
🎓 University & Online Courses
Here are structured paths you can take:
🧠 Proof & Logic (for beginners)
-
Intro to Mathematical Thinking / Proof Techniques (many universities offer these as “bridge” courses)
-
Discrete Mathematics (widely offered for CS majors)
📊 Algorithms & Theoretical CS
-
Introduction to Algorithms (often two semesters: design and analysis)
-
Data Structures & Algorithms (proofs of correctness and complexity)
🧪 Deeper Into Theory
-
Computability & Complexity (why some problems can or can’t be solved efficiently)
-
Proof Assistants / Formal Verification (Lean, Coq, Isabelle)
GitHub lists like awesome‑theoretical‑computer‑science collect many courses and lecture notes in math/CS theory if you want organized references.
🧠 Tips for Sequencing Your Learning
-
Start with proof books — Hammack, Velleman, Houston
-
Move into discrete math / logic — Rosen, Concrete Math
-
Take algorithm design seriously — CLRS, Skiena
-
Explore advanced theory or formal systems if you want rigor like in research
Thursday, March 05, 2026
harvard
Vijay Janapa Reddi just put the entire ML Systems (CS249r)
Book - mlsysbook.ai/book/
https://github.com/harvard-edge/cs249r_book
Philosophy of Computer science book
AI Researcher Links Abstract Thinking to Body's Physical Mapping
https://leodemoura.github.io/blog/2026/02/28/when-ai-writes-the-worlds-software.html
Discovering New Theorems via LLMs with In-Context Proof Learning in Lean
https://www.quantamagazine.org/building-the-mathematical-library-of-the-future-20201001/ - linarith, library search tactic
Wednesday, March 04, 2026
gpu
https://x.com/drscotthawley/ - chunk sigreg slices
majority of gpu cycles in python
https://www.doubleai.com/research/doubleais-warpspeed-surpassing-expert-written-kernels-at-scale - distribution of error in human code different from
https://leodemoura.github.io/blog/2026/02/28/when-ai-writes-the-worlds-software.html
A Stochastic Rounding-Enabled Low-Precision Floating-Point MAC for DNN Training
Formal Verification of an Iterative Low-Power x86 Floating-Point Multiplier with Redundant Feedback
https://x.com/MankyDankyBanky/status/2028923461213798724 - tiled matrix multiplication on GPU
Monday, March 02, 2026
updates
What They Understand Well
1) Memory hierarchy intuition (HBM → VMEM → registers)
That mental model is good.
On modern TPUs (including v5e), the simplified flow is:
HBM (off-chip DRAM) → On-chip SRAM (VMEM) → Vector / scalar registers → Compute units (VPU/MXU)
The kitchen analogy works conceptually.
What’s especially good:
-
They understand every operation must eventually happen in registers.
-
They understand data movement dominates performance.
-
They recognize tiling is required because VMEM and registers are limited.
That’s foundational systems thinking.
2) Parallelism intuition (8×128 tiles, 1024 elements)
Correct spirit.
The VPU processes large vector widths (implementation details vary slightly by generation), but the key idea is:
TPUs are throughput machines. They operate on wide tiles, not scalars.
That mental shift — from scalar programming to tile programming — is huge.
3) VPU vs MXU execution model
This is a strong observation:
-
VPU → synchronous, elementwise ops
-
MXU → asynchronous matrix multiply pipeline
The important concept they caught:
You can overlap scalar/vector work with MXU matmuls.
That’s essentially understanding latency hiding via pipeline parallelism.
That is exactly how high-performance kernels are written.
Very good.
4) BlockSpec + grid explanation
This explanation is clean and mostly accurate:
-
block_shape→ tile size -
index_map→ mapping grid coords to array slice -
grid→ launch dimensions
And yes:
grid_index × block_shape = offset into tensor
That’s correct at a conceptual level.
5) Softmax tiling insight
This is 100% correct:
Never tile across the reduction dimension unless you know how to handle partial reductions.
Softmax reduces across columns (usually). So you:
-
Tile rows
-
Keep full reduction dimension intact
This is a core GPU/TPU rule too.
6) BF16 inputs, FP32 accumulators
Correct and important.
BF16:
-
8 exponent bits (like FP32)
-
7 mantissa bits
-
Same dynamic range, lower precision
Accumulating in BF16 would:
-
Introduce large rounding error
-
Cause catastrophic loss in reductions
All high-performance kernels accumulate in FP32.
This shows strong numerical awareness.
🔧 What Could Be Clarified or Made More General
Now let’s refine some details.
1) “Every operation follows HBM → VMEM → VREG”
Conceptually true — but performance engineers think differently:
The real goal is:
Move data from HBM as few times as possible.
Good kernels:
-
Load once from HBM
-
Reuse heavily in VMEM / registers
-
Write back once
So a more precise framing:
Instead of:
Every op follows that path
Better:
All data originates in HBM, but high-performance kernels maximize reuse in on-chip memory to avoid going back.
The difference matters.
2) “MXU runs asynchronously”
Yes — but nuance:
It’s not free parallelism.
It works because:
-
The scalar unit issues MXU instructions.
-
The MXU has its own deep pipeline.
-
The compiler/runtime schedules around it.
The overlap works only if:
-
Dependencies allow it.
-
You structure the kernel to expose independent work.
So the deeper insight:
Asynchrony only helps if you create independent instruction streams.
Otherwise you just stall.
3) Softmax tiling rule — generalize it
Instead of:
Never tile along a dimension you're reducing over.
More general:
You can tile reduction dimensions — but then you must:
-
Compute partial reductions
-
Store partial sums
-
Perform a second reduction pass
So the full rule is:
Tiling across reduction dims increases algorithmic complexity and synchronization cost.
They learned the simplified case. The advanced version is worth adding.
4) Missing concept: Bandwidth vs Compute Bound
They’re close to a big “aha” but didn’t state it:
There are two kernel regimes:
Compute-bound
MXU saturated
Performance limited by FLOPs
Memory-bound
HBM bandwidth limited
Performance limited by bytes/sec
Softmax is often memory-bound.
MatMul is compute-bound (if sized well).
This distinction is foundational in inference engineering.
🧠 Extra “Ahas” They’re Ready For
These would level them up.
🔥 Aha 1: Tiling Is About Reuse, Not Fitting
Many beginners think:
We tile because memory is small.
Real reason:
We tile to maximize arithmetic intensity.
Arithmetic intensity = FLOPs / bytes moved.
MatMul works because:
-
Each loaded value participates in many multiply-adds.
-
So compute dominates memory cost.
Softmax has low reuse → often bandwidth bound.
That mental shift is huge.
🔥 Aha 2: MXU Is a Systolic Array
The MXU isn’t just a fast matmul unit.
It’s a systolic array:
-
Data flows rhythmically across a 2D grid.
-
Multiply-accumulate units arranged spatially.
-
Partial sums propagate across the array.
That explains:
-
Why tile shapes matter.
-
Why alignment matters.
-
Why padding matters.
🔥 Aha 3: Kernel performance is scheduling + memory choreography
The best TPU kernels:
-
Double buffer VMEM
-
Prefetch next tile while computing current tile
-
Overlap MXU with VPU
-
Avoid bank conflicts
-
Align shapes to hardware tile sizes
The game is not just math.
It’s choreography.
🔥 Aha 4: Inference vs Training
If they’re reading inference engineering:
Key difference:
-
Training → needs backward pass + activation storage
-
Inference → cares about latency + throughput
Softmax in inference:
-
Often fused
-
Sometimes avoided entirely (logits used directly)
Kernel design differs.
Sunday, February 22, 2026
PIM GPT
Session 23 AI accelerators ISSCC 2025
https://fpga.org/2014/12/31/the-past-and-future-of-fpga-soft-processors/
https://notes.ekzhang.com/events/nysrg - computer systems
https://cacm.acm.org/research/deconstructing-the-bakery-to-build-a-distributed-state-machine/
https://www.developing.dev/p/turing-award-winner-on-working-with
Design of a GPU with Heterogeneous Cores for Graphics
https://dyahadila.github.io/blog/2026/industry-job-search-cs-phd/
https://pages.cs.wisc.edu/~fredsala/cs639/schedule.html
DeepSeek gpus' vram only needs to hold a single layer's worth of kv vectors to serve a request
https://www.lesswrong.com/posts/MNpBCtmZmqD7yk4q8/my-understanding-of-anthropic-strategy
Friday, February 20, 2026
Tuesday, February 17, 2026
Compute Conference
mode collapse and mode dropping.
SIMD yield from disciplining the programmer into writing branchless functions and pipelines - good thread
SWAR SIMD-within-a-Register Arithmetic
real gap between hyperscale GPU scheduling (frontier clusters) and the everyday reality of small research labs running long single-GPU jobs.
Short answer:
-
overlaps with GPU context preemption, memory oversubscription, and gang scheduling, but today’s systems don’t expose a clean, transparent “pause/resume GPU job” abstraction.
-
There is research on this — just scattered across OS, ML systems, and datacenter scheduling literature rather than in one clean textbook chapter.
Let’s unpack it.
1. Is the Idea Plausible?
Conceptually, yes — but with sharp edges.
Its combining:
-
GPU page tables
-
NVIDIA Unified Virtual Memory (UVM)
-
NVIDIA Multi-Process Service (MPS)
-
Host-side suspension of the CPU process
-
Demand paging back to device memory
In theory, this gives you:
Coarse-grained GPU job preemption (tens of seconds)
via memory eviction + host suspension
The key insight is important:
You don’t need millisecond-level SM preemption.
You need coarse-grained fairness and priority enforcement.
That’s much more tractable.
2. Why This Is Hard in Practice
The core problems:
(A) GPU Context Isn’t Just Memory
Even if memory can be paged:
-
Kernel state
-
In-flight work
-
Streams
-
CUDA graphs
-
Allocator metadata
-
Device-side malloc
-
cuDNN/cuBLAS internal workspaces
These aren’t always safely “freeze-dried.”
GPU drivers do support context switching, but:
-
It’s optimized for graphics + short compute kernels
-
Not for long-running ML training loops
(B) Page Thrashing Would Be Brutal
UVM paging over PCIe:
-
~12–32 GB/s (PCIe)
-
~900 GB/s (HBM)
So paging device memory to host is ~30–70× slower bandwidth.
If a low-priority job pages back in 40 GB of model state, you’ve just paid a huge penalty.
But — if switching is infrequent and intentional (tens of seconds), this may be acceptable.
This becomes a policy problem:
-
When to evict?
-
When to preserve?
-
When to checkpoint instead?
(C) GPUs Are Built for Throughput, Not Preemptibility
CPU OSes evolved around:
-
Fast context switch
-
Full memory virtualization
-
Demand paging as first-class
GPUs evolved around:
-
Huge batches
-
Massive parallel throughput
-
Long kernels
Preemption was not the primary design goal.
3. This Is an Active Research Area
The idea intersects with several areas:
1️⃣ GPU Preemption Research
Look for work on:
-
Fine-grained GPU preemption
-
Kernel slicing
-
Thread block level preemption
Search terms:
-
"GPU kernel preemption"
-
"GPU context switching overhead"
Many papers out of systems conferences (OSDI, SOSP, ASPLOS).
2️⃣ Cluster-Level GPU Scheduling
A lot of this appears in ML systems research:
-
USENIX OSDI papers
-
ACM SOSP / ASPLOS
-
USENIX ATC
Look at systems like:
-
Gandiva (time-slicing DL training jobs)
-
Tiresias (GPU cluster scheduling)
-
Salus (fine-grained GPU sharing for DL)
These explicitly try to solve:
Short job first scheduling for GPUs
They often:
-
Time-slice at iteration boundaries
-
Require framework integration (e.g., PyTorch hooks)
Which is exactly what you’re trying to avoid.
3️⃣ OS Textbooks That Cover Foundations
No mainstream OS textbook deeply covers GPU preemption yet, but these are foundational:
-
Operating Systems: Three Easy Pieces
(Best conceptual grounding in scheduling + memory) -
Modern Operating Systems
(Classic coverage of preemption + VM)
For GPU-specific material:
-
“Heterogeneous Computing” courses (advanced grad level)
-
Papers from ASPLOS / ISCA / MICRO
4. The Deep Insight
The strongest idea expressed is this:
Coarse-grained, memory-driven GPU job suspension is “good enough.”
That’s actually a very practical engineering perspective.
You don’t need:
-
Fine-grained SM warp preemption
-
Transparent kernel-level swapping
You need:
-
“Pause at iteration boundary”
-
Evict memory
-
Resume later
Which suggests a hybrid model:
-
Driver-level memory eviction
-
Framework-level safe points
-
Scheduler-level policy
5. What Would Make This Realistic?
If I were designing this for a modest research cluster:
Practical Path:
-
Force iteration-boundary synchronization
-
Inject scheduler checks in training loops
-
Use CUDA context destruction + memory release
-
Reload from checkpoint
That’s ugly — but stable.
memory-based freeze/resume could work if:
-
GPU driver exposed explicit "evict context"
-
CUDA allocator was virtualized via shim (as you suggest with MPS)
-
Frameworks cooperated minimally
But today, that’s not officially supported.
6. Why NVIDIA Doesn’t Prioritize This
Nvidia would prefer you to Just Buy More GPUs!
There’s some truth there — but also:
-
Hyperscalers want multi-tenant utilization
-
Research clusters are a smaller market
-
Preemption reduces peak throughput
-
Hardware simplicity favors non-preemptive design
That said, with GPU scarcity cycles, this problem becomes more important.
7. If You Want to Dive Deeper
Search for:
-
“Gang scheduling for GPUs”
-
“Preemptible deep learning jobs”
-
“GPU memory oversubscription”
-
“Time-slicing deep learning workloads”
Look up papers like:
-
Gandiva (Microsoft Research)
-
Salus
-
Tiresias
Most are conference papers, not textbooks.
8. My Take
idea is:
-
Technically informed
-
Feels feasible at coarse granularity
-
Underexplored for small clusters
-
Very aligned with real pain points in academia
The hardest part isn’t paging.
It’s defining:
-
Safe preemption boundaries
-
Consistent device state
-
Allocator determinism
-
Avoiding pathological thrashing
But as a research direction? Completely legitimate.
If you’d like, I can:
-
Sketch what a “minimal viable preemptible GPU runtime” would look like
-
Or point you to specific seminal papers in this area
-
Or evaluate whether this could be a publishable systems paper idea
This is exactly the kind of idea that turns into a good ASPLOS paper.
Subscribe to:
Comments (Atom)